Für die Umsetzung unseres Vorhabens werden viele Daten in Form einer große Sammlung von Artikeln zum Thema
Flüchtlingskrise und den dazu verfassten Nutzer-Kommentaren benötigt.
Für Aufbau der Datenbasis verwenden wir so genannte Web-Scraping Techniken mit denen
wir die Kommentare direkt von den untersuchten Plattformen abgreifen. Dabei werden sowohl journalistischen
Nachrichtenportalen als auch alternative publizistische Internetseiten miteinbezogen. Bei der Auswahl der Plattformen
spielte auch die technische Komplexität des Auslesens eine Rolle, d.h. Plattformen, die ein vergleichbar
einfacheres Auslesen der Daten gestatten, wurden bevorzugt. Plattformen wie
Bis zum
Artikel
von Internetseiten
Kommentare
bis zum 30. Juni 2016
Technische Umsetzung
Die Implementierung des Web-Scraping erfolgte mithilfe von Scrapy umgesetzt, einem populären Web-Scraping Framework. Zum Durchsuchen der jeweiligen Plattformen nach relevanten Artikeln und Kommentaren setzen wir ein zweistufiges Verfahren ein:
- Stufe 1: Identifizieren von Artikeln zum Thema Flüchtlinge
- Stufe 2: Extrahieren der Kommentare zu den jeweiligen Artikeln
Pro Stufe und Nachrichtenplattform gibt es genau eine sogenannte Web Spider, welche die benötigten Daten automatisch aus den Internetseiten ausliest. Diese müssen speziell für jede Internetseite programmiert werden, denn das Vorgehen unterscheidet sich von Plattform zu Plattform. Alle Web Spiders werden regelmäßig ausgeführt, sodass neu veröffentlichte Artikel und Kommentare zeitnah erfasst und in die Datenbasis aufgenommen werden.
Selbstverständlich sammeln wir nur Kommentare, die für jedermann öffentlich einsehbar und verfügbar sind. Beim Sammeln beachten wir, falls vorhanden, die Vorgaben der Betreiber der jeweiligen Plattform. So werden keine Daten gesammelt, wenn dies in den Geschäftsbedingungen oder in der robots.txt verboten ist. Auch Schutzmaßnahme gegen eine Überlastung des Web-Servers umgehen wir nicht. Stattdessen sind unsere Web Spider so programmiert, dass Sie möglichst wenig Ladelast auf den abgefragten Webseiten erzeugen.
und Rauch
210
4.617
260
4.415
Online
328
11.764
Magazin
543
7.984
Times
4584
27.497
Online
3.959
75.857
Welt
1.944
13.628
Freiheit
333
2.745
626
11.054
Allgemeine
19
52
991
3.678
Tagesspiegel
229
4.478
1.921
182.625
Online
5812
25.792
Das Projekt Cyberhate-Mining fokussiert auf Kommentare zu Artikeln, die einen Bezug zur Flüchtlingskrise haben. Zur Identifizierung der geeigneten Artikel im Rahmen des Web-Scraping, kamen drei unterschiedliche Strategien zum Einsatz:
- Filterung relevanter Artikel über die Suchfunktion der Nachrichtenseite
- Beschränkung der Web Spider auf die entsprechende Themenseite, z.B. Zeit Online oder Epoch Times
- Durchsuchen gefundener Artikel nach festgelegten Stichwörtern
Einige Nachrichtenseiten und Blogs bieten eine Suchfunktion an, mit deren Hilfe sich nach Begriffen wie „Flüchtlingskrise“ oder „Flüchtlinge“ suchen lässt – manchmal wird die Verwendung dieser Suche jedoch durch die robots.txt untersagt. Mit Flüchtlings-Themenseiten oder Dossiers ist es möglich nur die dort verlinkten Artikel zu berücksichtigen. Für Plattformen, die weder Suchfunktion noch Themenseiten bereitstellen, wird ein Schlüsselwort-Verfahren eingesetzt. Die Relevanz jedes Artikels wird anhand eines oder mehrere Schlüsselwörter ermittelt, welche im Text vorkommen müssen.
Precision und Recall
Der Begriff Precision wird hierbei zur Bestimmung der Qualität genutzt, denn er gibt an, wie viele Elemente eines Ergebnisses tatsächlich richtig erkannt wurden. So könnte der Algorithmus im unten stehenden Beispiel etwa neun Artikel erkannt haben, welche er als relevant für die Flüchtlingsdebatte einstuft. Da jedoch nur fünf dieser Artikel wirklich relevant sind, ist die Precision nur 55.5%. In anderen Worten bedeutet dies nichts anderes, als dass das Verfahren unsaubere/schlechte Ergebnisse liefert.
Bis zu diesem Punkt können wir jedoch nur Aussagen über die Qualität des Ergebnisses treffen, jedoch fehlt neben der qualitativen Bewertung der Ergebnisse noch eine quantitative Einordnung. Genau diese Einordnung wird typischerweise mit dem Begriff Recall vorgenommen. Dieser beschreibt, wie viele Elemente ein Verfahren aus der Menge möglicher richtiger Elemente zurückgibt. Auf unser Projekt bezogen beschreibt der Recall den Anteil an Artikeln zum Themenbereich Flüchtlinge, den unser Crawler aus allen existierenden Artikeln einer Plattform zu diesem Thema findet. Im vorliegenden Fall bedeutet dies, dass nur fünf von vierzehn möglichen Elementen gefunden wurden.

Ein Blick auf die gesammelten Daten verrät bereits einiges über die untersuchten Plattformen und deren Kommentatoren. Journalistische Internetseiten veröffentlichen mehr Artikel zur Flüchtlingskrise als die meisten alternative publizistische Internetseiten. Spitzenreiter ist Zeit Online mit mehr als 5.8001) Artikeln, gefolgt von Epoch Times und Focus.de2). Im Zeitverlauf ist ein Ausschlag im September 2015 sowie im Januar und Februar 2016 bei vielen der Internetseiten erkennbar. Bei den Kommentaren ist dieses Phänomen erst mit geringer Verzögerung festzustellen. Welt.de ist Spitzenreiter mit der größten Anzahl an Kommentaren von über 180.000. Ihr folgen Epoch Times und Focus.de. Die längsten Diskussionen sind auf Welt.de zu finden. Hier gibt es im Durschnitt fast 100 Kommentare je Artikel.
Bewertungsverfahren
Es ist nach wie vor ziemlich schwierig, automatisiert Emotionen wie Hass in natürlich-sprachlichen Texten zu erkennen – aber auch nicht unmöglich. In den letzten Jahren wurden durch Verbesserungen in Algorithmik und Computer-Hardware neue Methoden entwickelt und bestehende Verfahren besser nutzbar.
Trotzdem kommt der Computer allein als neutraler Juror für die Erkennung von Hass-Kommentaren derzeit nicht in Frage. Um dennoch die für die Textanalyse-Tools notwendigen Einschätzungen der Kommentare zu erhalten, verwenden wir Nutzer-Bewertungen von realen Personen. Dieser so genannte Crowdsourcing-Ansatz ist nicht neu und wird bereits von anderen Wissenschaftlern verwendet.
Zum Lernen der Algorithmen benötigen wir möglichst viele bewertete Kommentare. Dennoch wird ein Kommentar
nicht sofort nach der ersten Nutzer-Bewertung als Hass  und Nicht-Hass
und Nicht-Hass  klassifiziert.
Um das Ausmaß der Subjektivität zu verringern, erheben wir bis zu sieben Bewertungen pro Kommentar.
Dadurch erhoffen wir uns einen passenden Ausgleich zwischen Quantität und Qualität der bewerteten Kommentare.
klassifiziert.
Um das Ausmaß der Subjektivität zu verringern, erheben wir bis zu sieben Bewertungen pro Kommentar.
Dadurch erhoffen wir uns einen passenden Ausgleich zwischen Quantität und Qualität der bewerteten Kommentare.
Nach jeder Bewertung wird überprüft, ob der entsprechende Kommentar einer aus drei Kategorien zugeordnet werden kann. Sind genug Bewertungen abgegeben, wird der Kommentar in eine der Kategorien „Hass“, „Kein Hass“ oder „Weiß Nicht“ eingeordnet.
Um die automatische Erkennung von Hass-Kommentaren zu ermöglichen, sind insbesondere Kommentare interessant, die von Nutzern als Hass identifiziert werden, damit sie anschließend gezielt in Textanalyse-Tools untersucht werden. Ein Kommentar ist als Hass-Kommentar kategorisiert, sobald zwei Bedingungen erfüllt sind:
- Drei Hass-Bewertungen
()
- Maximal eine Kein-Hass-Bewertung
()
Hass

...und weitere
Ebenso wie hasserfüllte Kommentare, benötigen wir auch gewöhnliche, hassunerfüllte Kommentare um Lerntechniken zur automatischen Erkennung von Emotionen zu entwickeln. Die Einstufung in die Kategorie „Kein Hass“ erfolgt analog zu Hass-Kommentaren. Folgende zwei Bedingungen müssen erfüllt sein:
- Drei Kein-Hass-Bewertungen
()
- Maximal eine Hass-Bewertung
()
Kein Hass
...und weitere
Es ist nicht immer möglich, eindeutig zu entscheiden, ob ein Kommentar hasserfüllt ist oder nicht. Sind sich Nutzer in den Bewertungen, die sie zu einem Kommentar abgeben, nicht einig, wird der entsprechende Kommentar weder als „Hass“ noch als „Kein Hass“ eingestuft, sondern der Kategorie „Weiß Nicht“ zugeordnet. Dies geschieht, sobald eine der folgenden Bedingungen erfüllt ist:
- Die ersten zwei Bewertungen sind „Weiß Nicht“
()
- Es gibt zwei mehr „Weiß Nicht“-Bewertungen als übrige Bewertungen
(
)
- Es werden zwei Hass- und zwei Kein-Hass Bewertungen abgegeben
(
)
Weiß Nicht
...und weitere
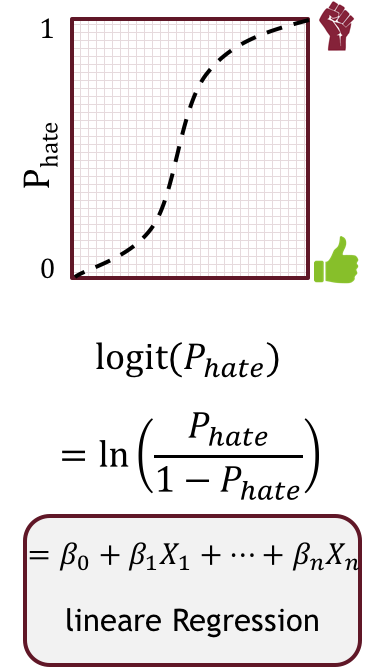
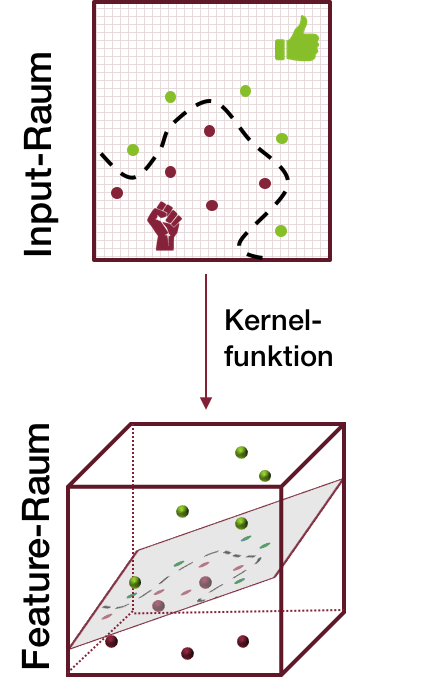
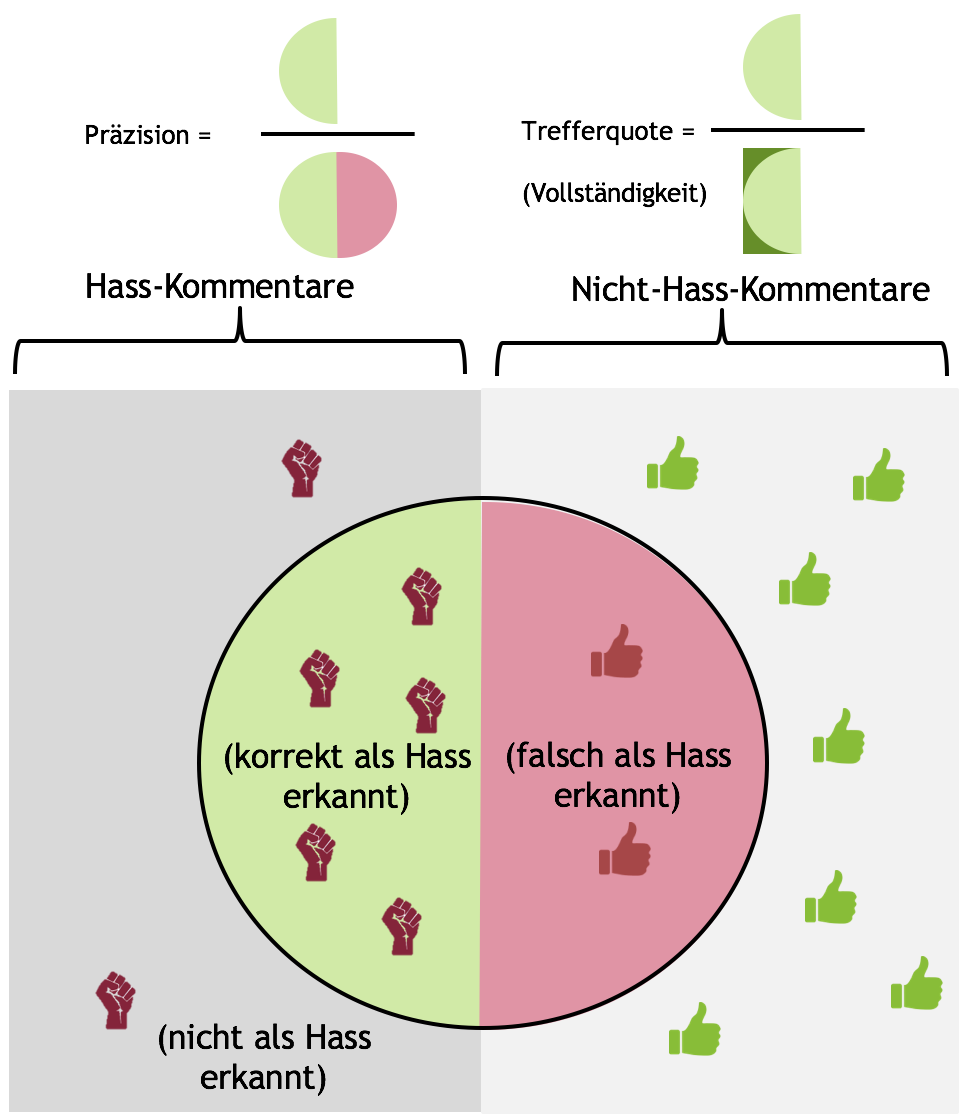
Diagrammerklärung
Das Diagramm zeigt wo am meisten kommentiert wird. Dazu stellt es die über den Erhebungszeitraum gesammelten Kommentare aggregiert je Plattform dar.